해당 원문을 공부하면서 직접 번역한 내용입니다. 정확하지 않은 표현과 필자가 본인의 이해를 위해 추가로 적은 내용들이 있으니 그 점 유의하시기 바랍니다.
우선순위 큐를 구현하는데 Heap을 더 선호하는 이유: https://codingmon.tistory.com/23
Heap은 binary tree(BST와 유사한)와 닮았다.
Heap은 트리이고, 모든 노드는 0, 1, 2개의 자식들을 가지고 있다.
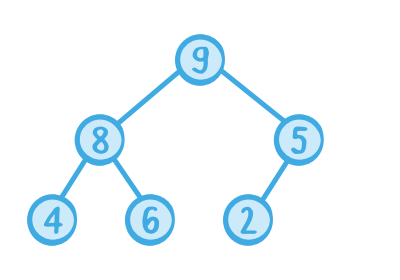
Heap의 요소들은 그들의 우선 순위에 따라 부분적으로 정렬돼있다. 트리의 모든 노드는 각 노드의 자식들보다 높은 우선순위를 가진다. 이 우선순위를 나타내는 두가지 다른 방식이 있다.
- maxheaps: 높은 값이 더 높은 우선순위
- minheaps: 낮은 값이 더 높은 우선순위
Heap은 compact한 높이도 가지고 있다.

새로운 level이 추가되기 이전에, 모든 기존에 존재하는 level은 모두 full 상태여야한다.
Heap에 새로운 노드를 추가할 때는 언제나, leftmost possible position부터 넣어줘야한다.
힙에 노드들을 삭제할 때마다는, 언제나 가장 하단의 level의 오른쪽 끝(rightmost node from the lowest level)부터 삭제해주어야한다.
Removing the highest priority element
힙은 **priority queue(우선순위 큐)**로 아주 유용하다. 왜냐하면 트리의 root노드가 힙에서의 가장 높은 우선순위를 가진 요소를 가지고 있기 때문이다.
하지만, 루트 노드를 제거하는 것만으로는 힙이 남지 않습니다. 아니 오히려, 그것은 두 힙을 남길 것이다.

대신에, 우리는 root노드를 힙의 마지막 노드와 swap한 후에 지운다.

그리고 나서 우리는 새로운 new root노드를 각각의 자식들과 비교해서, 더 높은 우선순위를 가진 자식과 다시 swap한다.

(maxheap이기 때문에 자식들 중 더 우선순위가 높은(값이 큰) 8과 swap하는 모습이다.)
이제 new root노드는 트리에서 가장 높은 우선순위를 가진 노드가 됐지만, 힙은 아직 모두 정렬되지 않았다. 새로운 new child node는 다시 해당 노드의 자식들과 각각 비교해서 더 우선순위가 높은 자식과 swap한다.
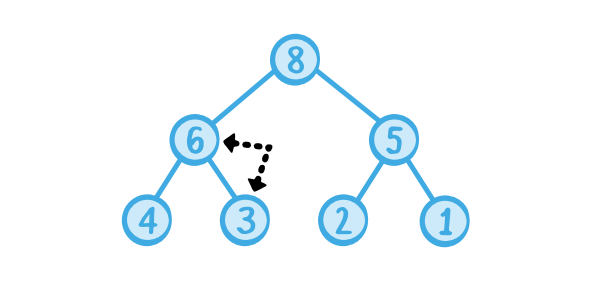
우리는 남은 자식들보다 우선순위가 높거나, leaf node(최단말 노드)가 될 때까지 계속해서 sift down한다. 모든 노드가 다시금 각각의 자식들보다 높은 우선순위를 가지게 된다면, 힙이 다시 restore된 것이다.
Adding a new element
새로운 요소를 더하는 것은 비슷한 기술을 활용한다.
첫번째로, 우리는 새로운 요소를 힙의 불완전한 level의 가장 왼쪽에 위치시킨다.
(we add the new element at the left-most position in the incomplete level of the heap)
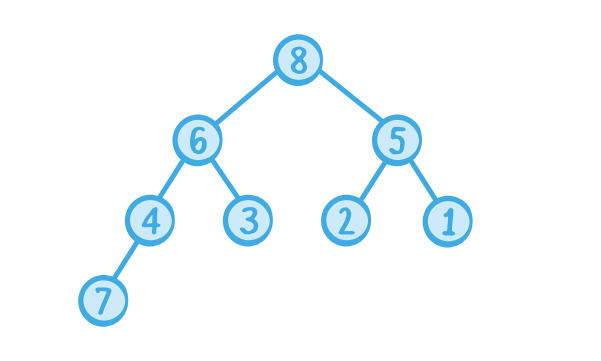
그리고, 우리는 추가한 노드의 부모와 우선순위를 비교하고, 만약 새로운 노드가 더 높은 우선순위를 가진다면, sift up(swap)을 해준다.

우리는 새로운 요소가 해당 부모보다 낮은 우선순위를 가지거나, 힙의 root노드가 될 때까지 계속해서 sift up해나간다.
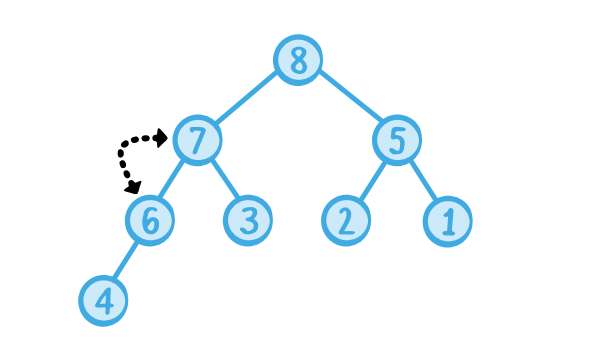
(6보다 7이 높으니 sift up, 그리고 root노드의 값, 8보다는 작으니 해당 위치 유지)
Practical Representation
만약, Binary Search Tree를 공부했다면, 힙 자료구조는 element와 자식들에 대한 Links를 가지고 있을 Node data type을 가지고 있지 않다는 것에 놀랐을 수도 있을 것이다. 속을 들여다보면 (Under the hood), 힙 자료구조는 사실상 배열이다 !
힙의 모든 노드에 인덱스가 할당된다. 우리는 root노드에 0을 할당하는 것으로 시작하고, 왼쪽에서 오른쪽으로 세면서, level을 내려가면서 세어서 내려간다.
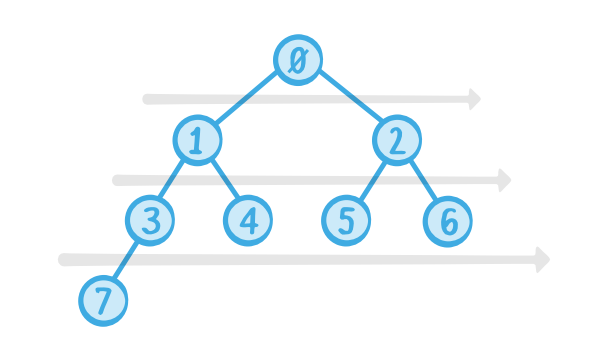
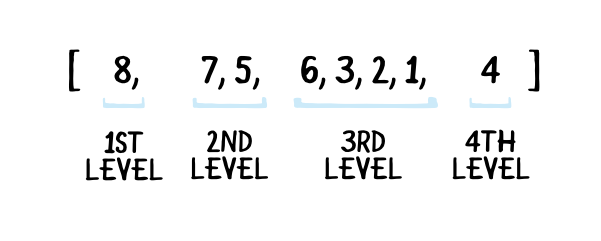
만약, 우리가 저 indices(indexes)들로 배열을 만든다면(element는 해당 index에 대한노드의 값), 아래와 같을 것이다.

어느 노드에서나 자식의 indices들 계산하는 작은 공식이 있다.
만약, 해당 노드의 인덱스 i가 주어졌다고 했을 때, 왼쪽 자식의 index는 2i + 1이고 오른쪽의 자식 노드는 2i + 2가 된다. (root node의 인덱스를 0이라고 했을 때)
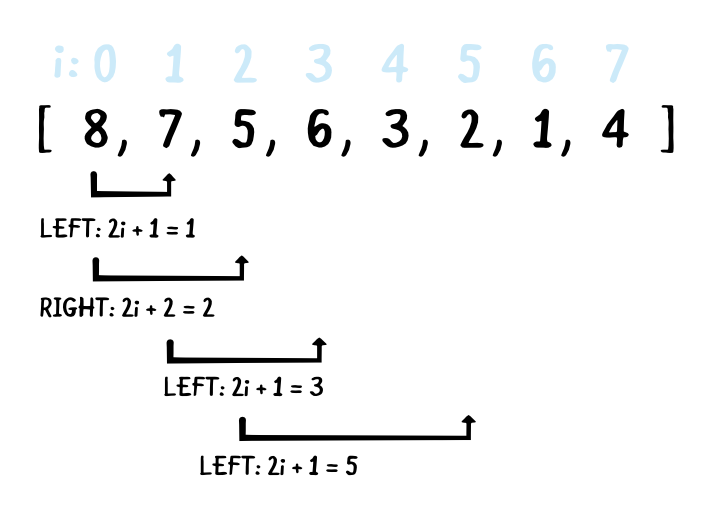
이것이 힙이 compact tree가 될 수 있는지, 왜 우리가 새로운 요소를 왼쪽에서부터 채워넣어야하는지에 대한 이유이다: 우리가 실제로 배열에 새로운 요소를 추가할 때, 사이에 gap을 놔두고 추가할 수 없다.
(we’re actually adding new elements to an array, and we can’t leave any gaps)
<aside> 💡 Note: 이 배열은 정렬되지 않았다. 위의 다이어그램으로 눈치챘을 수도 있지만, 힙이 관심을 가지는 유일한 노드간의 관계는 오직 그들의 자식들보다 높은 우선순위를 가지는 부모들에 대한 관계이다. 힙은 왼쪽 자식과 오른쪽 자식 어떤 자식이 더 높은 우선순위를 가지는지에 대해서는 관심이 없다. 그렇기에 항상 루트 노드에 가까운 노드가 먼 노드보다 우선순위가 높은 것을 말하는 것은 아니다.
</aside>
Implementating a Swift Heap
이제 Swift로 Heap을 구현해보자 (드디어!!)
struct Heap<T> {
var elements: [T]
let priorityFunction: (T, T) -> Bool
// TODO: priority queue functions
// TODO: helper functions
}
힙은 두가지 properties를 가지고 있다.
Generic 타입의 배열 elements와 priority function.
priority function은 두 인자를 받고 만일 첫번째 인자가 두번째 인자보다 더 높높다면 true를 반환하는 함수이다.
Simple functions
var isEmpty : Bool {
return elements.isEmpty
}
var count : Int {
return elements.count
}
func peek() -> T? {
return elements.first
}
직관적인 기능을 하는 함수들이라 peek만 가볍게 설명하고 넘어가겠다.
- peek(): 배열의 첫번째 요소를 return
- caller가 힙에서 가장 높은 우선순위를 가진 요소에 접근할 수 있도록 한다.
func isRoot(_ index: Int) -> Bool {
return (index == 0)
}
func leftChildIndex(of index: Int) -> Int {
return (2 * index) + 1
}
func rightChildIndex(of index: Int) -> Int {
return (2 * index) + 2
}
func parentIndex(of index: Int) -> Int {
return (index - 1) / 2
}
위의 네가지 함수들은 부모와 자식 노드의 index들을 계산하는 함수들이다.
해당 함수들은 값이 아닌 index를 반환하고 있다는 점을 유의해야한다.
모든 왼쪽 자식들은 홀수 index를, 오른쪽 자식들은 짝수 index를 가지게 될 것이다.
Comparing priority
지금껏 이론에서, 우리는 그들의 부모와 자식 노드들의 우선순위를 많이 비교했었다. 이 섹션에서 우리는 노드와 그것의 자식들 중 가장 높은 우선순위 요소를 가르키는 노드의 인덱스를 결정한다.
func isHigherPriority(at firstIndex: Int, than secondIndex: Int) -> Bool {
return priorityFunction(elements[firstIndex], elements[secondIndex])
}
이 helper 함수는 priority function property의 wrapper이다. 만약 첫번째 인덱스가 두번째 인덱스보다 우선순위가 높다면 true를 return한다.
이 함수는 아래 두개의 comparison helper functions를 만드는데 우리에게 도움을 준다.
func highestPriorityIndex(of parentIndex: Int, and childIndex: Int) -> Int {
guard childIndex < count && isHigherPriority(at: childIndex, than: parentIndex)
else { return parentIndex }
return childIndex
}
func highestPriorityIndex(for parent: Int) -> Int {
return highestPriorityIndex(of: highestPriorityIndex(of: parent, and: leftChildIndex(of: parent)), and: rightChildIndex(of: parent))
}
첫번째 함수는 부모 노드는 배열의 유효한 index를 가지고 있다고 가정하고, 만약 자식 노드가 배열에서 유효한 index를 가지는 지 검사한다. 그리고 해당 index들의 노드들의 우선순위를 비교해서 더 높은 우선순위를 가진 노드의 유효한 index를 return한다.
두번째 함수 또한 부모 노드의 index는 유효하다고 가정하고 해당 노드의 왼쪽 자식과 오른쪽 자식들을 비교한다. 만약 노드들이 존재한다면, 해당 노드, 왼쪽,오른쪽, 셋 중 가장 높은 우선순위를 가진 노드의 index가 반환된다.
마지막 helper function은 또 다른 wrapper이다.
mutating func swapElement(at firstIndex: Int, with secondIndex: Int) {
guard firstIndex != secondIndex else { return }
elements.swapAt(firstIndex, secondIndex)
}
두 개의 index를 인자로 받고, 같은 인덱스를 swap하고자 한다면 런타임 에러가 발생하기 때문에 만약 두 index가 서로 다르다면 swap한다.
Enqueueing a new element
지금까지 유용한 helper function들을 모두 작성했다면, 이제 제일 중요한 함수들은 금방 작성할 수 있을 것이다. 우선 첫번째로 우리는 힙의 제일 마지막 위치에 새로운 요소를 넣고, sift-up하는 enqueue작업을 수행하는 함수를 작성할 것이다.
우선 큰 틀의 함수는 아래와 같다.
mutating func enqueue(_ element: T) {
elements.append(element) // 마지막에 요소 삽입
siftUp(elementAtIndex: count - 1) // sift-up
}
마지막 위치에 새로운 요소를 넣고, sift-up. 간단하다.
이제 siftUp함수에 대해서 살펴보자.
mutating func siftUp(elementAtIndex index: Int) {
let parent = parentIndex(of: index) // 1
guard !isRoot(index), // 2
isHigherPriority(at: index, than: parent) // 3
else { return }
swapElement(at: index, with: parent) // 4
siftUp(elementAtIndex: parent) // 5
}
이제 한 줄 씩 살펴보자 !
- 뒤에서 계속해서 여러번 쓰이기 때문에, 우리는 인자로 받은 index의 부모 노드의 index를 변수로 가지고 있는다.
- 노드의 root노드를 sift-up하지 않기 위해서 guard한다.
- 혹은 부모 노드가 우선순위가 높을 경우에 대해서 guard한다.
- 만약, 노드가 root노드도 아니고 부모보다 우선순위가 높을 경우에, 부모노드와 노드를 swap한다.
- 해당 함수는 종료 조건에 다다를 때까지 재귀적으로 호출된다.
Dequeueing the highest priority element
이제 sift-up을 했으니, sift-down도 할 수 있다
mutating func dequeue() -> T? {
guard !isEmpty else { return nil } // 1
swapElement(at: 0, with: count - 1) // 2
let element = elements.removeLast() // 3
if !isEmpty { // 4
siftDown(elementAtIndex: 0) // 5
}
return element // 6
}
해당 함수도 한줄 씩 살펴보자
- return할 첫번째 요소가 있는지 확인한다. 아무 요소도 없다면 nil을 return한다.
- 만약 dequeue할 요소가 있다면, 힙의 마지막 노드와 swap한다.
- 이제 마지막 위치로 dequeue할 노드를 옮겼다면, 배열에서 지워준다. return된 값을 element변수에 담아준다.
(removeLast()는 마지막 요소를 삭제하면서 해당 값을 return해주는 함수이다)
4. 만일 배열이 비어있지 않다면? 앞서 swap해줬던 root노드가 올바른 위치에 가게끔 sift-down을 root에서부터 수행한다.
5. 마지막으로 앞서 가장 우선순위가 높았던 노드를 dequeue해서 담아두었던 element 변수를 return한다.
이제 siftDown함수를 살펴보자.
mutating func siftDown(elementAtIndex index: Int) {
let childIndex = highestPriorityIndex(for: index) // 1
if index == childIndex { // 2
return
}
swapElement(at: index, with: childIndex) // 3
siftDown(elementAtIndex: childIndex)
}
해당 함수도 한줄씩 뜯어보자
- 첫번째로, 인자로 넘겨진 index에 해당하는 노드와, 그에 대한 자식 노드들 중 가장 우선순위가 높은 노드에 대한 index를 알아낸다.
- 만약 인자로 넘긴 index가 leaf node,즉 자식이 없다면 highestPriorityIndex(for:) 함수는 인자로 넘긴 index를 return할 것임을 기억하자.
- 만약 index와 함수에서 return된 index가 같다면, (leaf node) 더이상 sift-down하지 않고 return
- 그렇지 않고 서로 다르다면? 자식들 중 하나가 더 높은 우선순위를 가지고 있다는 것이다. 해당 노드와 swap하고 재귀적으로 sift-down을 수행한다.
One last thing
이제 유일하게 필수적으로 체크해야될 건 힙의 생성자이다. Heap은 struct(구조체)이고 기본적으로 init function이 주어지고, 아래와 같이 호출할 수 있다.
var heap = Heap(elements: [3, 2, 8, 5, 0], priorityFunction: >)
하지만 이렇게 되면 주어진 배열이 Heap에 맞게끔 돼있지 않다. 따라서 heapify과정이 필요하다.
init(elements: [Element] = [], priorityFunction: @escaping (Element, Element) -> Bool) { // 1 // 2
self.elements = elements
self.priorityFunction = priorityFunction // 3
buildHeap() // 4
}
mutating func buildHeap() {
for index in (0 ..< count / 2).reversed() { // 5
siftDown(elementAtIndex: index) // 6
}
}
- 명시적으로 init함수를 써주었다.
- priority function은 해당 함수가 끝나도 계속해서 구조체에서 해당 함수를 잡고 있기 때문에 @escaping을 명시해주어야한다.
- 명시적으로, 힙의 properties들에 인자들을 할당한다.
- 힙에 조건에 맞는 힙을 모두 만들면, init()함수를 마친다
- buildHeap()함수에서, 배열의 반에서부터 reverse하게 iterate한다. 따라서 힙의 첫번째 반은 힙의 부모 노드이다.
- 만약 heap의 매 level이 위의 level보다 두 배 더 많은 요소들을 가질 수 있다는 것을 기억한다면, 매 level은 해당 level보다 위에 있는 모든 level이 가진 요소들 보다 딱 한개 더 많은 요소를 가진다는 것을 알아낼 수 있다.
- 하나씩 모든 부모 노드를 각각 노드의 자식들과 sift down을 하면, 결국 높은 우선순위의 자식들을 root쪽으로 올리게 된다.
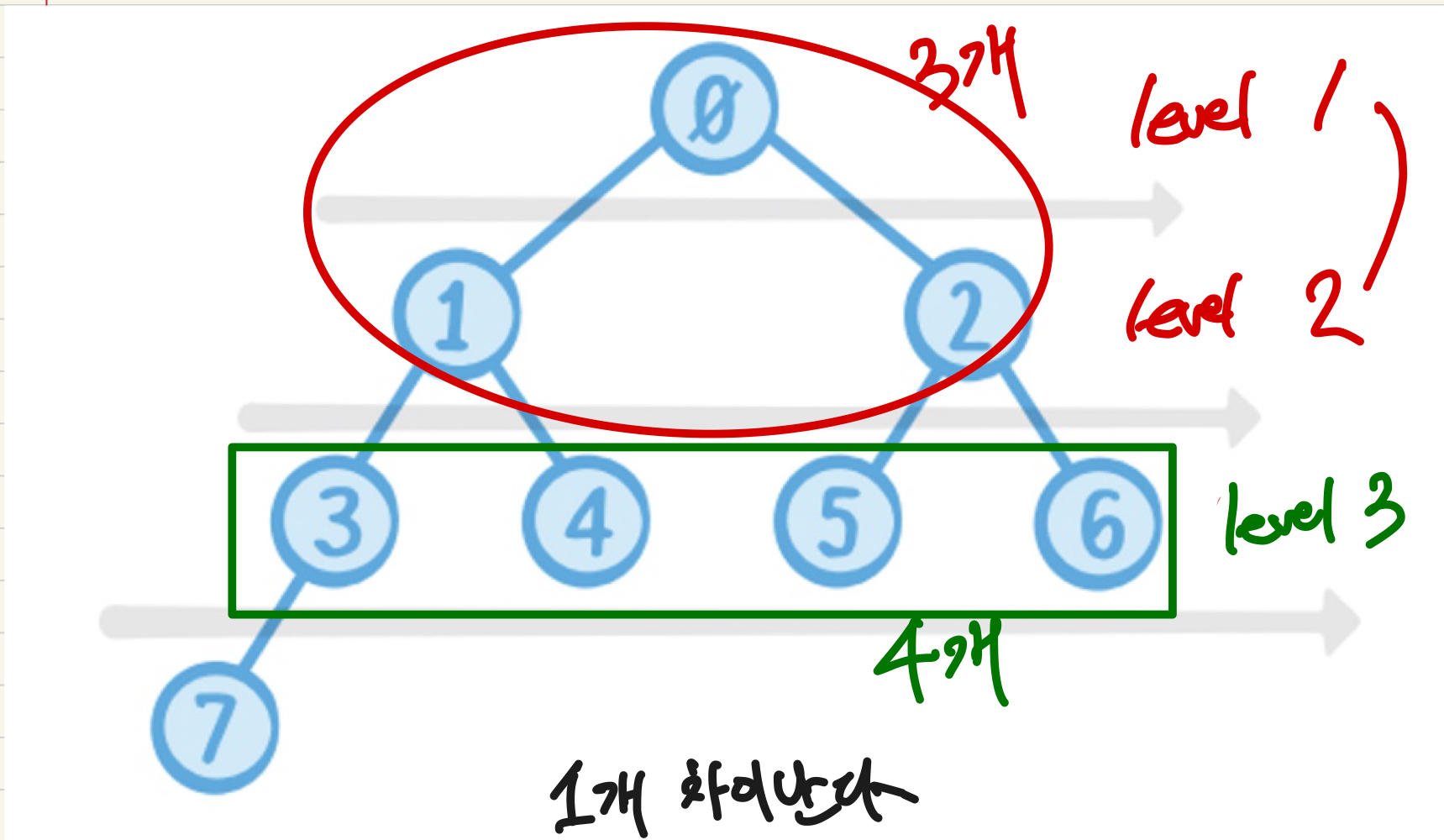
이제 끝!! 드디어 Swift로 Heap을 구현해보았다 !
A final thought
만약 거대한 힙을 가지고 있고, 힙이 빌 때까지 계속해서 높은 우선순위의 요소들을 dequeue한다면 어떤 일이 일어날까?
모든 요소들을 우선순위 정렬에 맞게 dequeue하게 될 것이고, 모든 요소들은 우선순위에 맞게 정렬될 것이다. 그것이 바로 heapsort 알고리즘이다 !
'CS > 자료구조' 카테고리의 다른 글
| LinkedList 정리 (Single, Double, Circular) (0) | 2023.08.09 |
|---|---|
| Stack 구현 (Array, LinkedList) (0) | 2023.08.04 |
| Queue 구현 (feat. Swift) (0) | 2023.02.07 |
| Priority Queue(우선 순위 큐)에서 Heap을 선호하는 이유 (0) | 2023.02.02 |



댓글