Linked List
List의 종류
- 배열(Array) 기반
- 연결(Link) 기반
배열 기반 리스트
- 장점
- 특정 위치의 데이터 조회가 빠르다
- 단점
- 데이터의 추가, 삭제 비용이 크다 (다 뒤로 밀거나 앞으로 당기거나..)
- 크기가 고정되어 있다.
맨 앞에도 쉽게 넣고 싶고, 맨 뒤에도 쉽게 넣고 싶은데..?
그럴 때 사용할 수 있는게 연결 기반 (linked) 리스트 !
연결 기반 리스트의 종류
- 단방향 연결 리스트 (Linked List라고 하면 기본으로 이것)
- 양방향 연결 리스트 (Double Linked List)
- Circular Linked List (원형 혹은 순환 연결 리스트)
- Circular single
- Circular Double
연결 기반 리스트
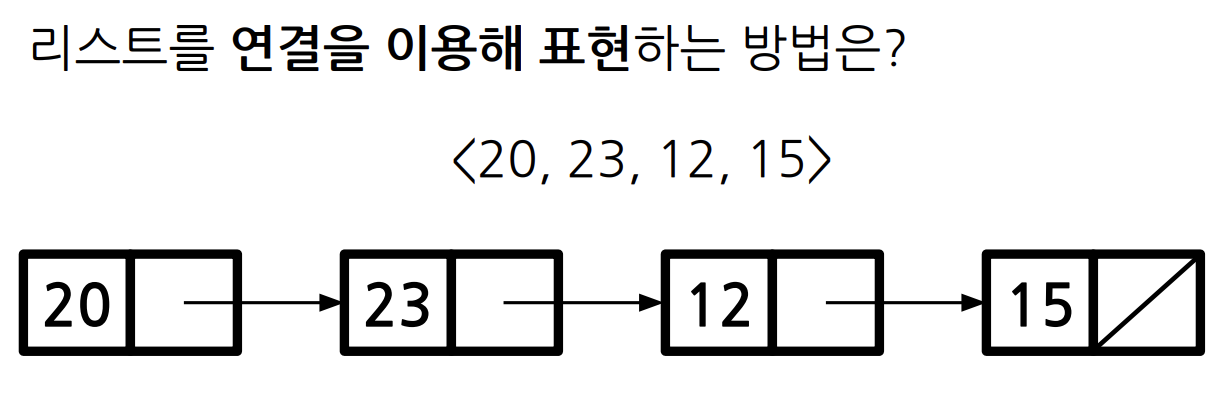
Node
Node는 데이터(Item)과 포인터(Pointer)로 구성된다.

연결리스트 구현 이슈

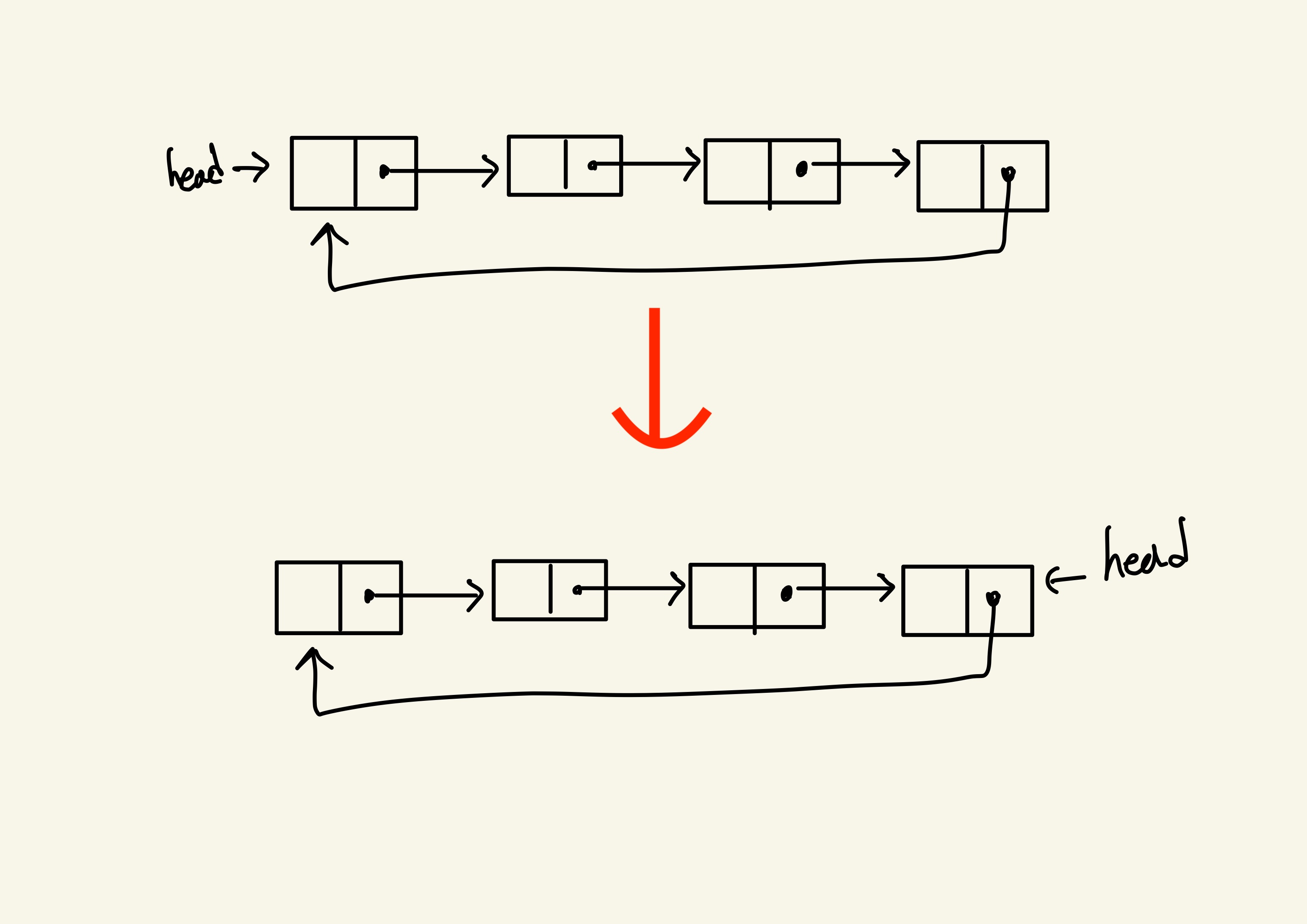
head를 따로 두냐 안두냐의 차이
→ 보통은 아래 방식처럼 head를 따로 두는 방법을 선호
아래처럼 head와 tail등을 따로 두게 되면 맨 처음과 끝에 넣는 작업도 결국에는 첫번째 혹은 마지막 노드와 head노드와 tail노드 사이에 노드를 집어넣는 ‘노드간 작업’으로 쳐서 항상 일관되게 작업을 할 수 있게 됩니다.
만약 위의 방법처럼 한다면, 매번 새로 추가될 때마다 head, tail을 옮겨줘야하기 때문에 해당 처리를 위한 분기가 필요하게 됩니다.
리스트의 구현방법에 따른 차이
| Array Based List | Array Based List | |
| 삽입/삭제 | O(n) | O(n) |
| 맨 앞에 삽입 / 삭제 | O(n) | O(1) |
| 맨 뒤에 삽입 / 삭제 | O(1) | O(1) |
| 메모리 오버헤드 Space overhead | O(n) : 케바케 | O(n) |
- Linkedlist의 경우 넣기 빼기 자체의 연산은 O(1)이지만 검색하는데 걸리는 시간복잡도가 O(n)이기 때문에 넣기, 빼기 또한 O(n)에 속한다.
- 메모리 오버헤드: 데이터를 저장하는 공간 이외에 추가적으로 더 사용하는 메모리 공간을 오버헤드라고 말한다.
- Linked List의 경우 메모리 오버헤드가 O(n)이다. 왜냐하면 아이템과 함께 링크가 있는데, 링크 또한 똑같이 4byte이고 아이템의 개수만큼 링크가 존재하기 때문이다. 그래서 만약 Item의 타입이 Int(4byte)이면 2배라고 할 수 있고, Item이 차지하는 바이트가 클수록 링크 자체가 가지는 영향은 작아진다.
보면 맨 앞에 넣고 빼는 동작을 할 때에 유의미한 차이가 있는 것을 알 수 있습니다.
따라서 후에 Queue같은 것을 구현할 때에는 실제로 Linked List를 많이 활용하게 됩니다.
왜? Queue는 양쪽에서 item을 꺼낼 수 있기 때문에!
순회
for i in 0..<myList.length; i++ {
print(myList.getValue(i))
}List에 있는 값들을 모두 순회하려면 ?
- ArrayList일 때의 시간복잡도: O(n)
- LinkedList일 때의 시간복잡도: O(n^2)
getValue는 앞에서부터 i 인자만큼 next, next…로 이동해서 값을 가져오기 때문.
흠..너무 비효율적인데???
pointer를 하나 만들어서 하나씩 가르키면서 값을 가져오면 되지 않을까?? 그러면 O(n)으로도 할 수 있을거 같은데? 🤔
→ Iterator 패턴 !
Iterator 패턴
리스트 순회
func search(at index: Int) -> Node<T>? {
var curr = 0
var currNode = head
while currNode != nil && curr < index {
currNode = currNode?.next
curr += 1
}
return currNode
}LinkedList를 좀 더 효율적으로 순회 하려면?
기존에 탐색할 때에는 head에서부터 next로 이동해가면서 원하는 값을 찾을 때까지 이동해야한다. 하지만 이 방법은 LinkedList일 때만 사용 가능한 방법!
사용자 입장에서는 그냥 List구나 하고 사용하게끔하고 안에 어떻게 구현이 되어있는지는 알필요가 없어야하는데, 이 방법은 LinkedList에만 한정된 방법이다. 이렇게 할꺼면 Abstract Data Type(ADT)가 왜 존재하지..?
그러면 아예 순회하는 기능 자체도 List의 하나의 요소로 보고 ADT에 넣어주자 → Iterator 패턴
ListIterator ADT
protocol ListIterator {
associatedtype T
func hasNext() -> Bool
mutating func next() -> T?
func hasPrevious() -> Bool
mutating func previous() -> T?
}let itr = myList.listIterator()
while (itr.hasNext()) {
let item: Int = itr.next()
print(item)
}- Array based List이든지, Linked based List인지 상관없이 위와 같이 일관된 방법으로 List를 순회할 수 있다.
구현
struct LinkedListIterator<T>: ListIterator {
private var curr: Node<T>?
init(head: Node<T>) {
self.curr = head
}
func hasNext() -> Bool {
if curr?.next != nil {
return true
}
return false
}
mutating func next() -> T? {
curr = curr?.next
return curr?.value
}
func hasPrevious() -> Bool {
return true
}
mutating func previous() -> T? {
return curr?.value
}
}Doubly Linked List
- 이중연결리스트, 양방향 연결 리스트
LinkedList의 한계
구현하면서도 이미 느꼈을테지만 previous로 가는 것이 너무 힘들다. 이전 노드로 이동할려면 처음부터 다시 출발해야하는 것이 비효율적이다. O(n)
‘반대 방향으로 순회하는 것을 더 빠르게 할 수 없을까’에 대한 고민의 해결책으로 나온 것이 이중 연결 리스트(Doubly Linked List) !

Circular Linked List

Circular Linked List는 모든 노드가 연결되어 원을 형성하는 LinkedList입니다. Circular Linked List에서 첫 번째 노드와 마지막 노드는 서로 연결되어 원을 형성하고 끝에
nil이 없습니다.
원형 연결 리스트는 어느 노드에서 시작해도 모든 노드를 탐색할 수 있을뿐만 아니라 순환적인 문제를 해결하는데 있어서 유용하게 쓰일 수 있는 자료구조입니다. (Circular Queue를 구현하는데도 사용됨.)
구조 설계
일단 위에 처럼 head가 첫 노드를 가르키는 상태면 맨 앞쪽에 노드를 추가하는 것은 쉬운데 마지막 노드 다음에 새 노드를 추가하기 위해서, 혹은 마지막 노드의 링크를 처음으로 옮기기 위해서 탐색이 필요하기 때문에 모든 LinkedList를 따라가야 하는 불편이 있습니다. (단방향 이기에 선행탐색이 힘듦)
그러면 어떻게 해야할까? head를 맨 뒤로 보내버린다, 즉 tail 느낌의 포인터로 활용하면 됩니다.
그러면 맨 앞에 삽입하는 것도 용이하고 마지막에 삽입하는 것도 매우 용이합니다.
맨 앞에 넣는 메서드 push
다른 글들에서는 insert_first로 많이 쓰는것 같음.

Empty 상태일 때
T: 새로 추가될 노드를 뜻함.next: 다음 포인터, 즉 그림에서 화살표를 뜻한다고 보면 됨.
T.next = T
head.next = T- 자기 자신을 next로 가지고 있는 모양으로 새로운 노드를 만들고
- 마지막 또한 해당 노드로 설정.
Not Empty상태 일 때
필요한 코드는 단 두줄이다.
T.next = head.next.nexthead.next.next는 마지막 노드의next, 즉 첫번째 노드를 가리킨다. 따라서 첫번째 노드를next로 설정
- [
head.nex](http://head.next)t.next = T- 마지막 노드의 next는 첫번째 노드여야하기 때문에 T를 가르킴으로써, 맨 앞에 넣는 작업 완료.
맨 뒤에 넣는 메서드 append
T.next = head.next.next // 1
head.next.next = T // 2
head.next = T // 3- T의 next를 기존의 마지막 노드가 가르키고 있는 next, 즉 첫번째 노드를 가르키게끔 합니다
- 마지막 노드의 다음을 T로 설정합니다. 왜냐하면 마지막에 추가한 것이기 때문
- 마지막은 T라고 이제 알려줍니다.
'CS > 자료구조' 카테고리의 다른 글
| Stack 구현 (Array, LinkedList) (0) | 2023.08.04 |
|---|---|
| Queue 구현 (feat. Swift) (0) | 2023.02.07 |
| Heap 구현 (feat. Swift) (0) | 2023.02.05 |
| Priority Queue(우선 순위 큐)에서 Heap을 선호하는 이유 (0) | 2023.02.02 |



댓글