Protocol Oriented Programming (POP)
상속이나 참조 semantics없이 다형성 구현
protocol Drawable { func draw() }
struct Point: Drawable {
var x, y: Double
func draw() { }
}
struct Line: Drawable {
var x1, y1, x2, y2: Double
func draw() {}
}
var drawables: [Drawable] = []
for d in drawables {
d.draw()
}class SharedLine: Drawable {
var x1, y1, x2, y2: Double
func draw() {
// ...
}
}- class도 물론 프로토콜을 사용할 수 있지만, reference semantic에 의해 의도치 않은 상태 공유가 일어나는 것을 원치 않기에 여기선 필요없다. class도 protocol을 채택할 수 있다는 사실만 알아가자.

여전히 우리 코드는 다형성이 유지가 되고 있다. 하지만 이전과 비교했을 때 한가지 다른 점이 있다.
value type인 struct Line과 struct Point는 V-Table dispatch에 필요한 공통 상속 관계(common inheritance relationship)를 공유하지 않는다.
그렇다면 어떻게 Swift는 올바른 메서드로 dispatch할까??
답은 Protocol Witness Table(PWT)이라고 하는 테이블 기반 메커니즘을 통해서 dispatch한다.
- 프로토콜을 구현하는 타입 하나당 테이블 하나를 가진다
- 그리고 해당 테이블의 항목은 타입 구현에 연결된다. 이제 메서드를 찾을 방법을 알았다.

하지만 아직도 의문이 남는다..
1. 배열의 요소에서 테이블로 이동하려면 어떻게 해야 할까?

2. Point는 2 words(x, y)의 사이즈를, Line은 4 words(x1, y1, x2, y2)의 서로 다른 사이즈를 가진다. 배열은 이 요소들을 배열에 고정된 offset에 요소를 균일하게 저장하려고 하는데 이게 어떻게 가능할까??
답은 Swift는 특별한 storage layout인 Existential Container를 사용한다.


- 해당
Existential Container의 처음 3 words는valueBuffer용으로 예약됩니다.
- 그렇기 때문에 2 words 사이즈의 Point는
valueBuffer안에 들어간다.
- 하지만
Line은 4 words 이기 때문에 사이즈가 맞지 않는다.
그렇다면 Line은 어떻게 저장해야하지??

- Swift가 메모리를 힙에 할당하고 값을 힙에 저장한 후, 해당 메모리에 대한 포인터를 컨테이너에 저장한다.
Line과 Point에는 보다시피 차이가 있는데, Existential Container는 어떻게든 이 차이를 manage해야하는데 어떻게 하는걸까??

이 경우에도 table based mechanism이 사용되는데, 이것을 우리는 Value Witness Table(VWT)라고 부른다.
- VWT는 value의 생명주기를 관리하고, Type당 하나의 테이블이 있습니다.
VWT 테이블이 어떻게 작동하는지 알아보기 위해 지역변수의 생명주기에 대해 살펴보자
allocate

- protocol 타입의 지역 변수의 생명주기의 시작에는, Swift가 테이블 안에 allocate function을 호출한다.

- Line 구조체를 저장해서 데이터는 힙에 저장하고 해당 메모리에 대한 포인터를
Existential Container가 가지고 있는 모습. allocate function을 통해 이 과정이 이루어졌다.
copy

- 다음으로 Swift는 로컬 변수를 초기화하는 할당 소스(source of assignment)의 값을
Existential Container에 복사해야 합니다.
- 여기에
Line이 있으므로 우리의Value Witness Table의 복사 항목(copy entry)은 올바른 작업을 수행하고 힙(stack아닌가??? 왜 힙이라고 말했지?)에 할당된valueBuffer에 복사합니다.
destruct

- 프로그램은 계속되고 지역 변수의 수명이 끝나면 Swift는
Value Witness Table의 destruct entry를 호출한다. 그러면 Type에 포함될 수 있는 값에 대한 참조 카운트(reference count)를 감소시킨다.
deallocate

- 마지막에 Swift가 테이블의 할당 해제(deallocate) 함수를 호출한다.
Line에 대한Value Witness Table이 있으므로 value를 위해 힙에 할당된 메모리를 할당 해제한다.
지금까지 Swift가 generically 다른 종류의 값들을 어떻게 다루는지 살펴보았다.
그러나 여전히, 어떻게 해당 테이블(Protocol Witness Table)에 도달해야 하는지는 의문이다.

Existential Container의 다음 entry는Value Witness Table에 대한 reference이다.
마지막으로 어떻게 protocol witness table로 도달할까??? 그건 바로

Existential Container의 마지막은,Protocol Witness Table에 대한 reference이다.
Existential Container 예시
지금까지 Swift가 프로토콜 유형의 value를 관리하는 방법을 살펴봤다. Existential Container가 작동하는 것을 보기 위해 예시를 살펴보자.
func drawACopy(local: Drawable) {
local.draw()
}
let val: Drawable = Point()
drawACopy(local: val)
// ------------------------------------------------
// Generated code
struct ExistContDrawable { // Existential Container
var valueBuffer: (Int, Int, Int) // 3 words 크기의 valueBuffer
var vwt: ValueWitnessTable // VWT에 대한 reference
var pwt: DrawableProtocolWitnessTable // PWT에 대한 reference
}

drawACopy(val)를 호출할 때, Swift 컴파일러에서 생성된 코드를 보면
- Swift가 인자의
Existential container를 함수로 넘겨주는 걸 확인할 수 있다

- 함수가 시작되면 해당 파라미터에 대한 지역 변수를 만들고, 인자를 할당한다. (
let local = val)

- Swift는
Existential Container를 stack 영역에 할당한다.
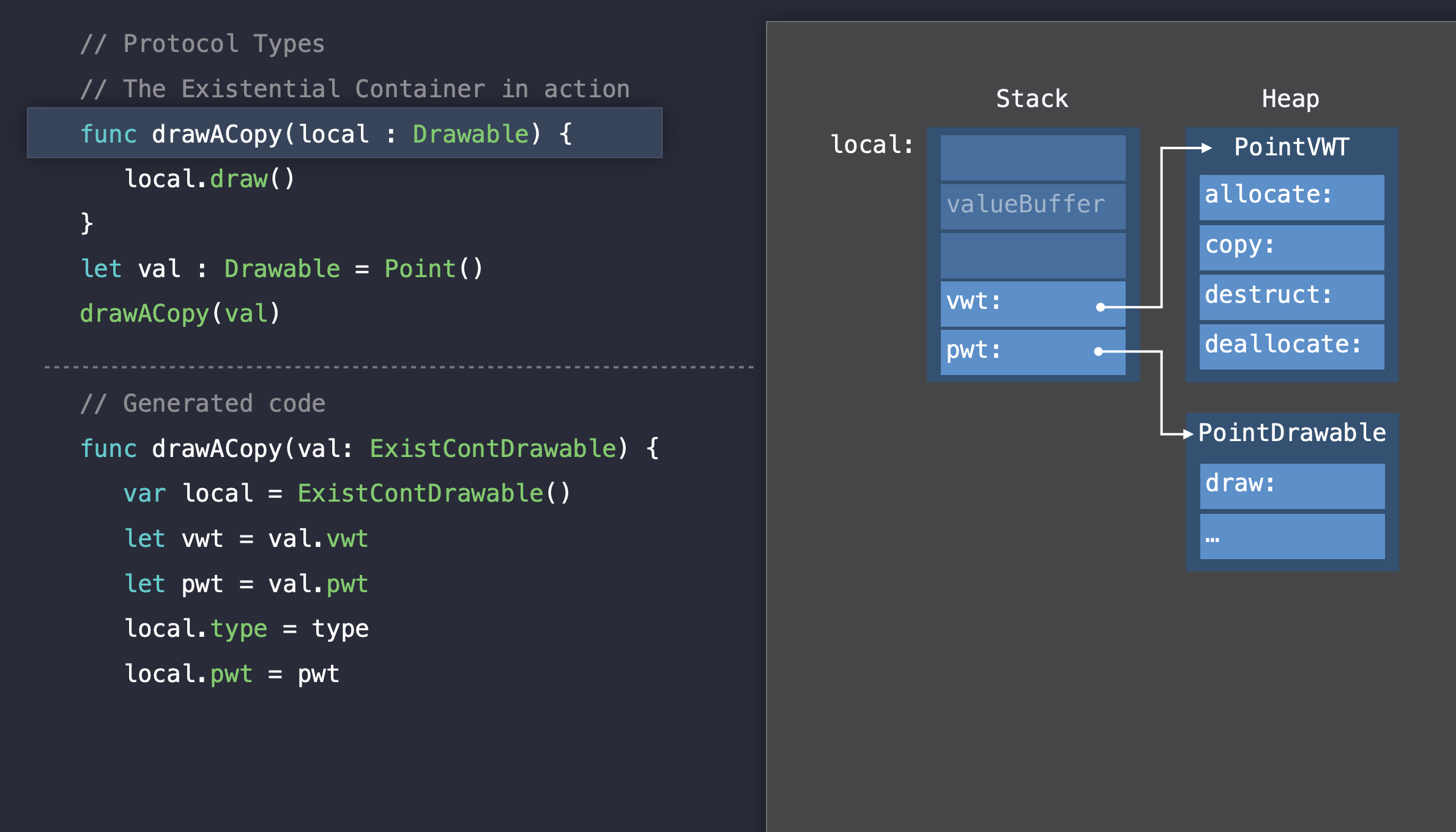
- 다음으로
Value Witness Table과Protocol Witness Table을 인자로 받은Existential Container로부터 읽고local existential container필드를 초기화한다.

- 다음으로 value witness 함수를 호출하여 필요한 경우 버퍼를 할당하고 값을 복사한다.
- 이 예제에서는 동적 힙 할당이 필요하지 않도록 Point를 넘겼다.
allocateBufferAndCopyValue함수는 인자의 값을Local Existential Container의valueBuffer로 복사한다.

- 만약
Line을 넘겼다면, 이 함수는 버퍼를 할당하고 거기에 값을 복사할 것이다.
- (힙에 값을 저장하고, 메모리 주소를 stack에 있는 valueBuffer에 저장한다.)

- 다음으로,
draw메소드가 실행되고 Swift는Existential Container의 필드에서Protocol Witness Table을 조회하고, 그 테이블의 고정 offset에서draw메소드를 조회하고, 구현으로 점프한다.
또 다른 Value Witness call, projectBuffer
pwt.draw(vwt.projectBuffer(&local))
이게 뭐지???
- pwt.draw 메서드는 입력으로 값 주소를 기대한다


- inline 버퍼에 맞는 작은 값인 경우?
Existential Container의 시작 위치
- inline
valueBuffer에 맞지 않는 큰 값일 경우?- 힙에 있는 주소가 시작위치
- 따라서, 해당 value witness함수(projectBuffer)는 타입에 따른 이러한 차이를 추상화한다.
- 모든 함수 실행이 끝나고, 지역변수의 생명주기가 끝나면 Swift는 value를 destruct하기 위해서 value witness함수를 호출한다.
- 값에 참조가 있으면, reference count를 줄이고 버퍼가 할당됐다면 버퍼를 할당 해제한다.
- stack이 제거되어, stack에 생성된 Local Existential Container 또한 제거된다.
여기서 한가지 알아둬야 하는 것은…
이 작업이 struct Line과 struct Point와 같은 값 타입들을 protocol들과 결합하여
을 얻을 수 있게 해주는 것이다.
우리는 drawable 프로토콜 유형의 배열에 Line과 Point 를 모두 저장할 수 있게 된다.
이러한 dynamism이 필요하다면, 이것은 지불하기에 좋은 가격이며 앞서 1부에서 우리가 본 예제와 같은 class를 사용하는 것과 비교됩니다. Class도 V-Table을 통과하고 reference counting의 추가 오버 헤드가 있기 때문이다.
지금까지 우리는 지역변수가 복사되는 방식과 protocol 타입 value에 대해 method dispatch가 작동하는 방식을 살펴보았다.
이제 stored properties(저장 프로퍼티)에 대해서 살펴보자.

Drawable프로토콜 타입의 저장 프로퍼티first와second가 있는 Pair 구조체가 있다.
Swift는 이 두 개의 저장 프로퍼티들을 어떻게 저장할까?
inline of the enclosing struct

Pair를 할당할 때, Swift는Pair를 저장하는데 필요한 두 개의Existential Container를 둘러싸는 인라인 구조체(inline of the enclosing struct)에 저장한다.

- 위 사진처럼 Point와 Line 구조체를 앞서 우리가 저장했듯이 저장할 수 있다.
- Point는 valueBuffer의 3 word안에 들어맞고, Line은 들어맞지 않기 때문에 힙에 값을 저장한다.
- 이렇게 사용하면 나중에 프로그램에서 다른 타입의 값을 저장할 수 있다.

- 이런식으로 다른 타입의 값을 저장할 수 있다
- 그런데 보면, heap allocation이 두번 일어난 것을 볼 수 있다
힙 할당 비용을 설명하기 위해 다른 프로그램을 살펴보도록 하자.

- 왼쪽의 코드를 위의 방법대로 진행시키면 오른쪽 다이어그램과 같은 결과가 될 것이다.
- 앞서 1부에서 우린 heap allocation은 비싸다는 것을 배웠다. 근데 위의 다이어그램에는 무려 4개의 heap allocation이 있다
다른 방법이 뭐가 있을까..

Existential Container에는 초기 3 words를 위한 자리가 있고, reference는 기본적으로 1 word이기 때문에 그 안에 들어갈 수 있다.
- 만약
Line이 class로 구현됐다면, reference에 의해 저장되고, 해당 reference는 valueBuffer에 들어갈 것이다.

- copy를 해도 이전처럼 heap allocation이 증가하는 것이 아니고 reference count만 증가하게 될 것이다.
- 하지만 이렇게 되면 second의 값을 바꾸면 first의 값이 바뀌어버리는 우리가 의도치 않는 상태 공유가 발생하게 된다.
우리는 value semantics을 원한다. 어떤 방법이 있을까??
copy and write 기술을 활용하면 된다.

- Class에 쓰기 작업(write)을 하기 이전에, 이것의 reference count를 확인한다.
- 만약 reference count가 1보다 많다?
- 해당 인스턴스를 copy한 이후에, 해당 copy에 write한다.
- 이렇게 하면 상태를 분리할 수 있다 (this will decouple the state)
copy and write을 이용해서 Line을 위해서 어떤 것들을 할 수 있을지 살펴보자 !

Line구조체의 모든 필드를 포함하는LineStorage라는 클래스를 만든다.
- 이 후에
Line구조체가 이LineStorage를 참조한다.
- 만약 우리가 값을 읽고 싶을 때 마다(read), 우리는 그저 storage안을 읽으면 된다.
- 만약 값을 수정하고 변형하고 싶다면?? 우선, reference count가 1보다 큰지 확인한다.
- 1보다 크다면? (
isUniquelyReferencedNonObjc호출이 판단한다)LineStorage의 copy를 만들고 난 이후에, 그것을 변형한다.
- 1보다 크다면? (
지금까지 우리는 어떻게 struct와 class를 결합하여 복사(copy)와 쓰기(write)를 사용하여 간접 스토리지(indirect storage)를 얻을 수 있는지 보았다.
이제 예제로 돌아와서 indirect storage를 사용하면 어떤 일이 일어나는지 살펴보자.

- 이번에는
LineStorageobject를 heap에 만들고,LineStorage를 향한 reference만 복사된다(reference count가 증가한다)
- 이것은 heap allocation보다 훨~씬 저렴하다 !!
Summary
Protocol Type - Small Value

만약 Existential Container의 valueBuffer inline에 딱 들어맞을 정도의 작은 값을 가진 프로토콜 타입이라면?
heap allocation은 발생하지 않는다.
만약 구조체가 어떠한 참조도 가지고 있지 않다면, 당연히 reference counting도 없을 것이고, 가장 빠른 코드가 될 것이다.
value witness 및 protocol witness table을 통한 indirection을 통해서, 우리는 동적인 다형성을 가능하게 하는 Dynamic dispatch의 모든 힘을 얻게 된다. (we get the full power of dynamic dispatch)
Large Value와 비교해보자
Protocol Type - Large Value

Large Value는 프로토콜 유형의 변수를 초기화하거나 할당할 때마다 힙 할당이 발생한다.
Large Value struct에 참조가 포함된 경우 잠재적으로 reference counting도 발생한다.

- copy되면서 heap allocation이 반복되는 안좋은 경우 (위의 예시에서 4개의 힙할당이 이루어진 부분)

- indirection(
LineStorage클래스)를 통해서 개선된 모습
- 비싼 heap allocation → 좀 더 싼 reference counting

- Protocol Type으로도 동적인 다형성을 제공한다
- 이것은
Value Witness Table과Protocol Witness Table과Existential Container를 통해 이루어진다
- Large Value를 copying하는 것은 heap allocation을 일으키지만, 간접 저장 및
copy and write기술을 사용해 구조체를 구현하여 이 문제를 해결할 수 있는 방법을 위에서 소개했다.

- 다시 예제로 돌아와서 우리는 항상 구체적인 타입으로 사용했다
Generic을 쓸 수 없을까?? 가능하다 !
Generic
Generic 타입의 변수가 저장되고 복사되는 방식과 method dispatch가 이러한 변수와 함께 작동하는 방식을 살펴보자 !

drawACopy가generic파라미터를 사용하는 것으로 바뀌었다.
- Generic 코드는 매개변수(parametric) 다형성이라고도 불리는, 좀 더 정적 형태의 다형성을 제공한다.
- One Type per call context. 호출 컨텍스트 당 하나의 타입.
- 이게 무슨 말일까?? 예시와 함께 살펴보자 !

- 함수가 실행될 때, Swift는 generic 타입 T를 call side에서 호출할 때의 타입과 binding한다. 이 예제에서는 Point와 바인딩한다.
foo함수가 실행되고bar의 함수 호출에 도달하면 이 로컬 변수는 방금 찾은 타입, 즉Point를 갖게 된다.

- 다시, 이 호출 컨텍스트의 일반 매개 변수 T는 유형 Point를 통해 바인딩된다. 보다시피, Type은 매개 변수를 따라 call chain 아래로 대체된다. (substituted down the call chain along the parameters)
- 이것이 보다 정적인 형태의 다형성 또는 매개변수 다형성을 의미한다.
Swift가 이걸 어떻게 구현하는지 더 자세히 들여다보자 !

Generic을 통한 one shared implementation이 있다.
protocol witness table과value witness table을 사용할 것이다.
- 하지만, call context 하나 당 하나의 타입을 가지기 때문에, Swift는
Existential Container를 사용하지 않는다.

- 대신에 call side에서 사용된 타입(예제에서는
Point)의Value Witness Table과Protocol Witness Table을 함수의 추가적인 인자로써 전달한다.

- 함수 실행 도중에, 파라미터를 위한 지역 변수를 생성할 때, Swift는 Value Witness Table을 사용해서 잠재적으로 필요한 모든 버퍼를 힙에 할당하고 할당 소스(source of the assignment)에서 대상으로 복사한다.

draw메서드를 사용할 때면,protocol witness table을 사용하여, table에서 고정된 오프셋에 있는draw메서드를 찾아서 해당 구현으로 점프한다.
- 여기에는 Existential Container가 없다. 그렇다면 어떻게 매개 변수를 위해 생성된 지역 변수에 대해 필요한 메모리를 할당할까???

- 방법은 valueBuffer를 stack에 할당하는 것이다.
- 작은 값은 3 words안에 딱 들어맞을 것이고, 큰 값이면 힙에 저장디고
local Existential Container내부에 해당 메모리에 대한 포인터를 저장한다.- 근데 아까
Existential Container는 없다고 말한거 아닌가??? 이건valueBuffer를 잘못말씀하신거 같은데??
- 근데 아까
Faster ??
이러한 정적인 유형의 다형성은 specialization of generics(Generic의 특수화)라고 불리는 컴파일러 최적화를 가능하게 해준다 !

- call side에 있는 Type을 사용한다.

- Swift는 해당 타입을 사용하여 함수의 generic 매개변수를 대체하고, 해당 타입에 맞는 구체적인 버전의 함수를 새로 생성한다. 아래와 같이 (Version per type in use)

- 이러한 코드는 굉장히 빠른 코드다.


- 그렇다면 코드 사이즈가 굉장히 많이 늘어나지 않을까 ?? (보자마자 이 생각했는데 뜨끔ㅋㅋ)
- static type의 정보는 컴파일러가 공격적으로 최적화를 할 수 있게끔 해주고, Swift는 잠재적으로 코드 사이즈를 줄일 수 있다 ! (앞서 1부에서 봤던 컴파일러 최적화처럼, call stack대신 그냥 구현한줄로 대체해버리는…inlining이라고 불리는 기술)
- 결국! 코드 사이즈가 늘어나는 것은 일어날 수도 있지만, 필수적으로 늘 그런 것은 아니다 !
지금까지 specialization이 어떻게 작동하는지 살펴봤는데, 그렇다면 언제 일어날까?? (WHEN)

- 이 코드를 specialization하기 위해 Swift는 이 call site에서 타입을 유추할 수 있어야 한다.
- 지역변수 → 생성자 를 통해서 Point로 초기화 됐음을 확인 할 수 있다 !
- 또한, Swift는 specialization 중에 사용되는 Type과 함수 - 사용 가능한 generic function 자체의 정의를 모두 가질 필요가 있다.
- 이 경우에서는 모두 한 파일에 정의돼있다 !
- 이는
전체 모듈 최적화(Whole Module Optimization)가 최적화 기회를 크게 개선할 수 있는 것이다.
왜그럴까?

Point에 대한 정의를 별도의 파일로 옮긴 상황이라고 가정하자.
- 두 파일을 별도로 컴파일하면,
UsePoint파일을 컴파일 할 때Point정의를 사용할 수 없다.

- 두 개의 파일을 하나의 유닛으로 묶어 같이 컴파일한다면,
Point파일의Point정의에 대한 통찰력이 생기게 되고 최적화를 할 수 있게 된다 !
- 이것이 최적화 기회를 굉장히 증가시킬 수 있기 때문에,
whole module optimization은 Xcode8(8이라니…지금 내가 쓰는게 14인데..)에서 default로 되어있다.
- 다시 예제로 돌아가자 !
다시 예제로


- 아래사진과 같이 제네릭 타입을 활용하면 동일한 타입의 쌍만 생성 하도록 강제할 수 있게 된다 (우리가 의도한 대로)
- 이렇게 하면 위에 사진처럼 나중에 한쌍의
Line묶음에Point를 저장할 수 없게 된다 !
- 성능면에서 이게 더 좋을지에 대해서 살펴보자 !

- 저장 프로퍼티들이 제네릭 타입을 가지고 있는 것을 볼 수 있다
- 런타임 중에서는 타입은 바뀔 수 없다는 것을 기억하자 !
- 생성된 코드에 대한 의미는 Swift가 enclosing 유형의 인라인 스토리지를 할당할 수 있다는 것이다.
- 따라서 한
Pair의Line을 만들 때Line의 메모리는 실제로 enclosing pair의 인라인에 할당된다.
- heap allocation이 필요가 없다 !
- 다른 타입을 저장할 수도 없다 의도한 대로 !

- Value Witness Table과 Protocol Witness Table을 사용하여 비전문화된 코드가 어떻게 작동하는지, 그리고 컴파일러가 어떻게 코드를 전문화(specialize)하여 일반 함수의 유형별 버전을 만들 수 있는지 살펴봤다.

- 구조체를 포함하고 있는 specialized generic code
- 구조체 타입을 사용하는 것과 동일한 성능을 가진다
- 구조체 타입의 값을 복사할 때 힙 할당이 필요하지 않다
- 구조체에 참조가 포함되어 있지 않다면 Reference counting도 없다
- 컴파일러 최적화를 추가로 가능케하고, 실행 시간을 줄이는 static method dispatch를 가지고 있다.

- Class와 성능면에서 동일
- 힙할당, reference counting, V-Table을 통한 dynamic dispatch

- 작은 값을 포함하는 특수화되지 않은 제네릭 코드
- Stack에 할당된 valueBuffer에 들어맞기 때문에 지역 변수에 힙 할당이 필요하지 않다
- value가 참조를 포함하고 있지 않는다면, reference counting도 없다
witness table을 사용하여 모든 잠재적 call site에서 하나의 구현을 공유한다.

- 큰 값과 제너릭 코드를 사용하는 경우 힙 할당이 발생한다
- 하지만 앞서 소개했듯이 indirect storage(앞서 예시에서의
LineStorage)를 활용할 수 있다
- 큰 값에 참조가 포함된 경우 reference counting이 생기고, dynamic dispatch의 힘을 얻는다. 즉, 코드 전체에서 하나의 구현을 공유할 수 있다
Summary

- 필요한 만큼의 최소한의 dynamism을 가지고 거기에 적합한 추상화를 선택해라 !
- 정적 타입 검사가 가능하고 컴파일러는 컴파일 타임에 프로그램이 올바른지 확인할 수 있다
- 추가로, 컴파일러가 코드를 최적화할 정보를 더 얻을 수 있기 때문에, 더욱 빠른 코드를 얻게 될 것이다
- Class를 사용해야하는 경우에는 1부 참조
- 프로그램의 일부가 좀 더 정적인 형태의 다형성을 사용하여 표현 될 수 있다면 Generic 코드와 value Type을 결합할 수 있고, 그렇게 하면 정말 빠른 코드를 얻을 수 있고 해당 코드에 대한 구현도 공유할 수 있다.
- 동적인 다형성이 필요하다면?? protocol 타입들과 value 타입들을 결합해서 value semantics를 여전히 사용하면서도! class에 비해 빠른 코드를 얻을 수 있다.
- 그리고 만약, Protocol 타입 혹은 Generic 타입 내에서 큰 값을 복사함으로써 생기는 heap allocation에 대한 문제가 있다면?
indirect storage with copy and write이 해결책이 될 것이다 !
결론
개인적으로 2부가 1부보다 훨씬 어려웠던 것 같다. 1부에서 V-Table을 활용한 메서드 동적 디스패치도 이해가 쉽지 않았는데, 테이블 메카니즘이 2부에서 훨씬 많이 나왔던 것 같다.
이런 기능들을 설명을 들었을 때 이해 하기도 쉽지 않은데 처음 만든 사람들은 대체 뭐지 싶은 느낌이다..해당 영상은 앞으로도 여러번 돌려봐야할 것 같다. 번역을 직접 내가 보면서 한 것도 앞으로 다시 볼 때에 더 수월하게 보기 위함이었다. 아무래도 내가 정리해야 어느 부분에 어떤 설명이 나왔는지 더 기억에도 남고, 설명이 더 머리에 오래 남는 것 같다. 일단 이번 세션은 여기서 마치고 다음주에 다시 다른 WWDC세션을 보고 정리할게 있다면 다시 정리해보도록 하겠다 !
'Dev > WWDC 정리' 카테고리의 다른 글
| [WWDC22] Design protocol interfaces in Swift (1) | 2023.04.27 |
|---|---|
| [WWDC19] Advances in Collection View Layout (Compositional Layout 정리) - 2(完) (1) | 2023.04.27 |
| [WWDC19] Advances in Collection View Layout (Compositional Layout 정리) - 1 (0) | 2023.04.27 |
| [WWDC18] iOS memory deep dive - 1 (1) | 2023.03.27 |
| [WWDC21] Use async/await with URLSession + 적용 (0) | 2023.03.23 |




댓글